无关变量|例子,类型和控件
在一个实验,一个随机变量是否有任何你没有调查的变量可能会影响你的研究结果。
如果不加控制,无关的变量会导致对两者关系得出不准确的结论自变量和因变量.他们还可以介绍各种各样的研究偏见尤其对你的工作选择性偏差
| 研究问题 | 外部变量 |
|---|---|
| 内存容量与测试性能有关吗? |
|
| 睡眠不足会影响驾驶能力吗? |
|
| 光照能提高老鼠的学习能力吗? |
|
为什么无关变量很重要?
无关的变量会威胁到内部效度为你的研究结果提供不同的解释。
如果没有考虑到这一点变量类型也会给你的研究带来许多偏差,尤其是选择偏差的类型,比如:
- 生存偏差:研究人员只关注成功个体(“幸存者”)的例子,而不是整个群体,从而得出结论。
- Nonresponse偏见:不回应调查的人与回应调查的人在很大程度上是不同的。
- 总量差额的偏见:当你的总体中的一些成员在样本中没有被代表。
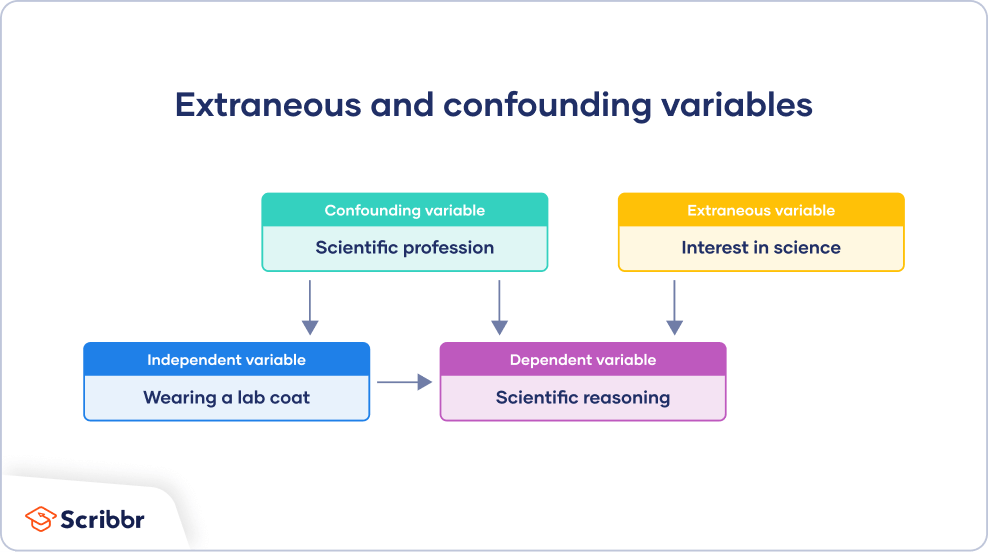
你从一所大学招募学生参与这项研究。你通过将参与者分成两组来操纵自变量:
- 参加实验组被要求在研究期间穿实验服。
- 参加对照组被要求在研究期间穿一件休闲外套。
所有参与者都要接受一个科学知识测试,并将他们的分数在两组之间进行比较。
当外部变量不受控制时,很难确定确切的变量影响自变量对因变量的影响,因为无关变量的影响可能会掩盖它们。
不受控制的外来变量也会使实验中看起来似乎有自变量的真实影响,但实际上并没有。
- 参与者的专业(例如,STEM或人文学科)
- 参加者对科学的兴趣
- 人口统计学变量,如性别或教育背景
- 测试的时间
- 实验环境或设置
如果这些变量在两组之间存在系统性差异,你就不能确定你的结果是来自你对自变量的操作,还是来自无关变量。
控制无关变量是一个重要方面实验设计.当你控制一个无关的变量时,你把它变成控制变量.
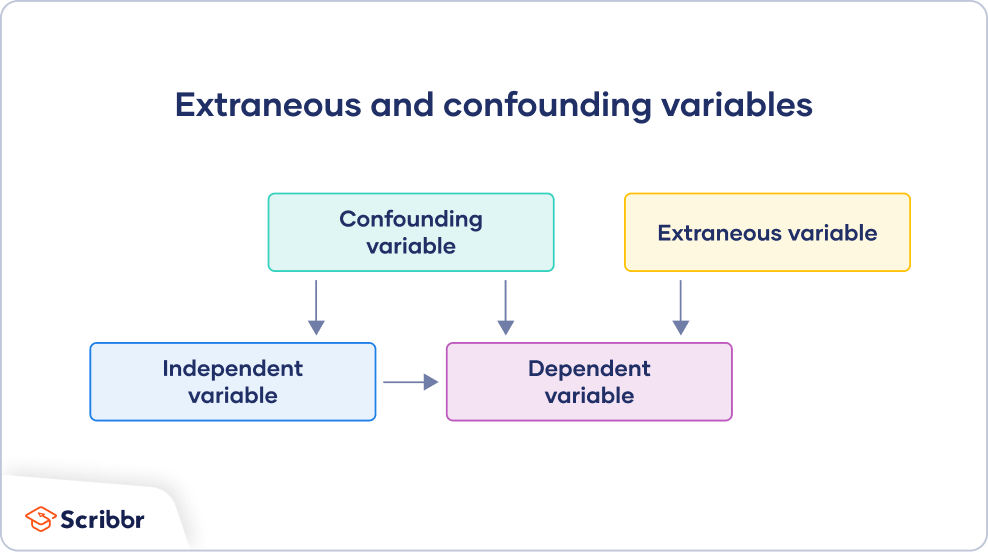
无关变量和混淆变量
一个混杂变量是一种与自变量和因变量都相关的无关变量。
- 无关变量是任何可以影响因变量的东西。
- 一个混杂变量影响因变量,和也与或相关的有原因地影响自变量。
在一个概念框架图中,你可以画一个箭头从一个混杂项指向自变量,也可以指向因变量。你可以画一个从无关变量到因变量的箭头。
在实验室工作的人通常会穿实验室大褂,一般来说,他们的科学知识可能更高。因此,你的操作不太可能提高这些参与者的科学推理能力。
只影响科学推理的变量是无关变量。这些因素包括参与者对科学和本科专业的兴趣。虽然对科学的兴趣可能会影响科学推理能力,但这与穿实验室大褂没有必然关系。
无关变量的类型和控件
需求的特点
需求的特点是鼓励参与者符合研究人员行为预期的线索。
有时,参与者可以推断出研究研究背后的意图,从材料或实验设置,并利用这些提示,以与研究假设一致的方式行动。这些需求特征可以偏见研究结果与降低外部效度,或普遍性的结果。
为了在测验中取得好成绩,他们会更加关注题目。
你可以通过让参与者难以猜测你的研究目标来避免需求特征。要求参与者执行不相关的填充任务或填写看似相关的调查,以引导他们偏离研究的真实本质。
实验者效应
实验者效应是研究人员可以影响研究结果的无意行为。
在那里有两种主要的实验者效应:
- 实验者与参与者的互动会在无意中影响他们的行为。
- 测量、观察、分析或解释中的错误可能会改变研究结果。
不鼓励穿非实验服的参与者在测试中表现出色。因此,他们在回答问题上没有那么努力。
为了避免实验者效应,你可以实现掩蔽(模板)对参与者和实验者隐藏条件分配。在双盲研究中,研究人员无法使参与者偏向于以预期的方式行事,或选择性地解释结果以适应他们的需求假设.
情境变量
情境变量,如照明或温度,可以改变参与者在学习环境中的行为。这些因素都是的来源随机误差或者是测量的随机变化。
为了理解自变量和因变量之间的真正关系,你需要减少或消除情境因素对学习结果的影响。
为了避免情境变量影响研究结果,最好在整个研究过程中保持变量不变,或者在分析中对它们进行统计解释。
参与者变量
参与者变量是参与者背景中任何可能影响研究结果的特征或方面,即使它不是实验的重点。
参与变量包括性别、性别认同、年龄、受教育程度、婚姻状况、宗教信仰等。
由于参与者之间的这些个体差异可能会导致不同的结果,因此测量和分析这些变量很重要。
要控制参与变量,您应该致力于使用随机分配分割你的样本分为对照组和实验组。随机分配通过均匀分布参与者特征使您的组具有可比性。
关于无关变量的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
班达里,P.(2022年12月05日)。无关变量|例子,类型和控件。Scribbr。检索于2022年12月14日,来自//www.charpingshvac.com/methodology/extraneous-variables/
