研究与统计中的变量类型|例子
在统计研究,变量被定义为研究对象的属性。选择衡量哪些变量是好的关键实验设计.
例子
如果你想测试某些植物物种是否比其他植物更耐盐,你可能测量的一些关键变量包括盐的量你往水里加入植物种类正在被研究,和植物健康相关的变量,比如增长而且枯萎.
您需要知道您正在使用的变量类型,以便选择合适的变量统计测试并解释你的研究结果。
你通常可以通过问两个问题来确定变量的类型:
数据类型:定量变量vs分类变量
数据是对变量的特定测量-它是您记录在数据表中的值。数据一般分为两类:
- 定量数据代表数量
- 分类数据代表分组
包含定量数据的变量是定量变量;包含分类数据的变量是分类变量.每一个变量类型可以细分为更多类型。
定量变量
当您收集定量数据时,您记录的数字代表可以加、减、除等的实际金额。有两种类型的定量变量:离散而且连续.
| 变量类型 | 这些数据代表什么? | 例子 |
|---|---|---|
| 离散变量(即整数变量) | 单个项或值的计数。 |
|
| 连续变量(又名比率变量) | 连续或非有限值的测量。 |
|
分类变量
分类变量表示某种类型的分组。它们有时被记录为数字,但这些数字代表的是类别,而不是事物的实际数量。
| 变量类型 | 这些数据代表什么? | 例子 |
|---|---|---|
| 二元变量(又名二分变量) | 是或不是结果。 |
|
| 名义变量 | 群体之间没有等级或顺序。 |
|
| 序数变量 | 按特定顺序排列的组。 |
|
*注意,有时一个变量可以作为多个类型工作!如果刻度是数字的,并且不需要保持为离散的整数,则序数变量也可以用作定量变量。例如,产品评论上的星级是有序的(1到5星),但平均星级是定量的。
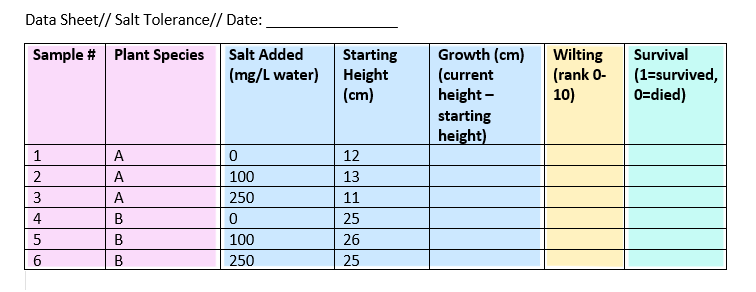
示例数据表
为了跟踪你的耐盐实验,你做了一个数据表,记录了实验中变量的信息,比如盐的添加和植物健康状况。
为了收集植物在一段时间内的反应信息,你可以每隔几天填写相同的数据表,直到实验结束。这个示例表是根据变量的类型进行颜色编码的:名义上的,连续,序数,二进制.
实验部分:自变量与因变量
实验通常是为了找出效果一个变量对另一个变量有影响——在我们的例子中,盐的添加对植物生长的影响。
你操纵独立变量(你认为可能是导致),然后测量因变量(你认为可能是效果),以找出这种影响可能是什么。
您可能还会有保持不变的变量(控制变量)以便专注于你的实验性治疗。
| 变量类型 | 定义 | 例(耐盐实验) |
|---|---|---|
| 独立变量(又名治疗变量) | 为了影响实验结果而操纵的变量。 | 添加到每种植物水中的盐量。 |
| 因变量(又名响应变量) | 代表实验结果的变量。 | 任何测量植物健康和生长的方法:在本例中是指植物高度和萎蔫率。 |
| 控制变量 | 在整个实验过程中保持不变的变量。 | 种植植物的房间里的温度和光照,以及给每一种植物的水量。 |
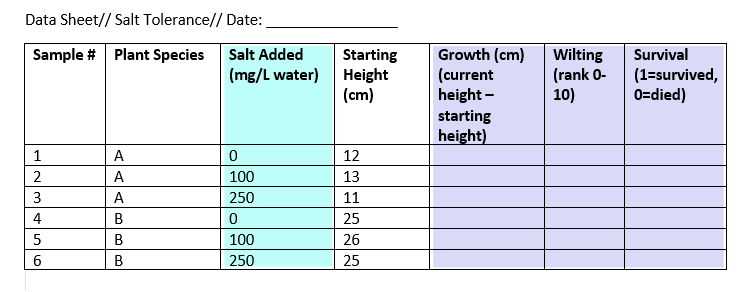
示例数据表
在这个实验中,我们有一个独立的和三个依赖变量。
表中的其他变量不能划分为独立变量或因变量,但它们确实包含解释因变量和自变量所需的数据。
那么相关研究呢?
当你这样做时相关研究,“依赖”和“独立”并不适用,因为你并没有试图建立因果关系(因果关系).
然而,在某些情况下,一个变量明显先于另一个变量(例如,降雨导致泥浆)比反之)。在这些情况下,您可以将前面的变量(即降雨量)称为预测变量而下面的变量(即泥浆)的结果变量.
其他常见的变量类型
一旦你定义了自变量和因变量,并确定它们是分类的还是定量的,你就能够选择正确的统计检验.
但是,还有许多其他描述变量的方法可以帮助解释结果。下面列出了一些有用的变量类型。
| 变量类型 | 定义 | 例(耐盐实验) |
|---|---|---|
| 混杂变量 | 在你的实验中,一个变量隐藏了另一个变量的真实影响。当另一个变量与你感兴趣的变量密切相关,但你在实验中没有控制它时,就会发生这种情况。要小心这些,因为混淆变量有很高的风险,引入各种各样的研究偏见尤其对你的工作忽略变量偏差. | 花盆的大小和土壤类型可能会影响植物的生存,甚至比盐的添加量更大。在实验中,你可以通过保持它们不变来控制这些潜在的混杂因素。 |
| 潜在的变量 | 不能直接测量,但可以通过代理表示的变量。 | 植物的耐盐性不能直接测量,但可以从我们加盐实验中对植物健康的测量中推断出来。 |
| 复合变量 | 在实验中由多个变量组合而成的变量。这些变量是在分析数据时创建的,而不是在测量数据时创建的。 | 这三个植物健康变量可以组合成一个单一的植物健康评分,以便更容易地展示你的发现。 |
关于变量的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
Bevans, R.(2022, 12月02日)。研究与统计中的变量类型|例子。Scribbr。检索于2022年12月17日,来自//www.charpingshvac.com/methodology/types-of-variables/
