多元线性回归|快速指南(示例)
回归模型通过拟合观测数据来描述变量之间的关系。回归允许您估计因变量如何随着自变量的变化而变化。
多元线性回归是用来估计的关系两个或多个自变量而且一个因变量.你可以使用多元线性回归,当你想知道:
因为你有两个自变量和一个因变量,所有的变量都是定量的,可以用多元线性回归来分析它们之间的关系。
多元线性回归的假设
多元线性回归的假设和简单线性回归:
方差齐性(同方差):我们预测的误差大小在自变量的值之间没有显著变化。
观察的独立性:数据集中的观测数据采用统计有效的方法收集抽样方法,变量之间没有隐藏的关系。
在多元线性回归中,有可能有些自变量实际上是相互关联的,因此在建立回归模型之前检查这些自变量是很重要的。如果两个自变量的相关性太大(r2 > ~0.6),那么在回归模型中只应该使用其中一个。
正常:数据遵循a正态分布.
线性:通过数据点的最佳拟合线是一条直线,而不是曲线或某种分组因子。
如何进行多元线性回归
多元线性回归公式
多元线性回归的公式为:

 =因变量的预测值
=因变量的预测值 = y轴截距(其他参数均为0时的y值)
= y轴截距(其他参数均为0时的y值) =回归系数(
)的第一个自变量(
=回归系数(
)的第一个自变量( )(也就是自变量值的增加对y预测值的影响)
)(也就是自变量值的增加对y预测值的影响)- =无论你测试多少个自变量,都做同样的事情
 =最后一个自变量的回归系数
=最后一个自变量的回归系数 =模型误差(也就是在我们的估计中有多少变化)
)
=模型误差(也就是在我们的估计中有多少变化)
)
 =因变量的预测值
=因变量的预测值 = y轴截距(其他参数均为0时的y值)
= y轴截距(其他参数均为0时的y值) =回归系数(
=回归系数( )的第一个自变量(
)的第一个自变量( )(也就是自变量值的增加对y预测值的影响)
)(也就是自变量值的增加对y预测值的影响) =最后一个自变量的回归系数
=最后一个自变量的回归系数 =模型误差(也就是在我们的估计中有多少变化)
=模型误差(也就是在我们的估计中有多少变化)为了找到每个自变量的最佳拟合直线,多元线性回归计算了三件事:
然后计算t统计和p模型中每个回归系数的值。
R的多元线性回归
虽然可以手工进行多元线性回归,但更常见的是通过统计软件来完成。在我们的例子中,我们将使用R语言,因为它是免费的、强大的,并且可以广泛使用。下载样例数据集,自己尝试一下。
负荷心。data数据集到您的R环境中,并运行以下代码:
heart.disease.lm < - lm(心。疾病~骑自行车+吸烟,data =心脏。data)
这段代码接受数据集heart.data然后计算自变量的影响骑自行车而且吸烟因变量是多少心脏病利用线性模型的方程:lm ().
通过遵循完整的分步指南来了解更多信息R的线性回归.
以下是学生们喜欢Scribbr校对服务的原因
解读结果
要查看模型的结果,可以使用总结()功能:
总结(heart.disease.lm)
这个函数从线性模型中获取最重要的参数,并将它们放入如下表:
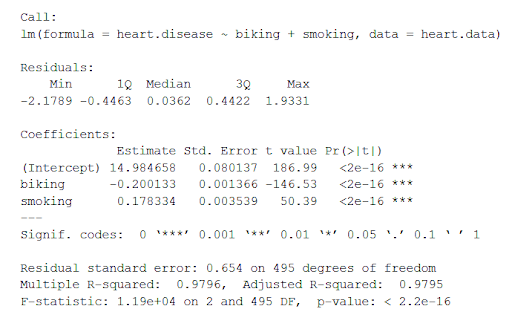
摘要首先打印出公式(' Call '),然后是模型残差(' residuals ')。如果残差大致以零为中心,且两边的分布相似,如上图所示(中位数0.03,最小值和最大值在-2和2左右),则模型可能符合异方差假设。
接下来是模型的回归系数(“系数”)。系数表的第一行是标签(截距)-这是回归方程的y截距。了解估计截距有助于将其代入回归方程并预测因变量的值:
在这个输出表中需要注意的最重要的事情是接下来的两个表——自变量的估计值。
的估计列是估计的效果,也叫回归系数或者r2价值。表中的估计数字告诉我们,骑自行车上班的人每增加1%,心脏病的发病率就会降低0.2%;吸烟人数每增加1%,心脏病的发病率就会增加0.17%。
的Std.error列显示标准错误估计。这个数字显示了回归系数估计值周围有多少变化。
的t值列显示检验统计量.除非另有说明,线性回归中使用的检验统计量为t价值来自两面t测验.测试统计量越大,结果偶然出现的可能性就越小。
的Pr(> | t |)列显示p价值.由此可见计算出的可能性有多大t如果参数无影响的零假设为真,则值将偶然出现。
因为这些值非常低(p在两种情况下都< 0.001),我们可以拒绝原假设并得出结论,骑自行车上班和吸烟都可能影响心脏病的发病率。
展示结果
当报告你的结果时,包括估计的效果(即回归系数),估计的标准误差,和p价值。你还应该解释你的数字,让你的读者清楚地知道回归系数的含义。
在图表中可视化结果
在结果中加入图表也会很有帮助。多元线性回归在某种程度上比简单线性回归更复杂,因为在二维图中有更多的参数。
然而,有一些方法可以显示包含多个自变量对因变量的影响的结果,即使实际上只能在x轴上绘制一个自变量。
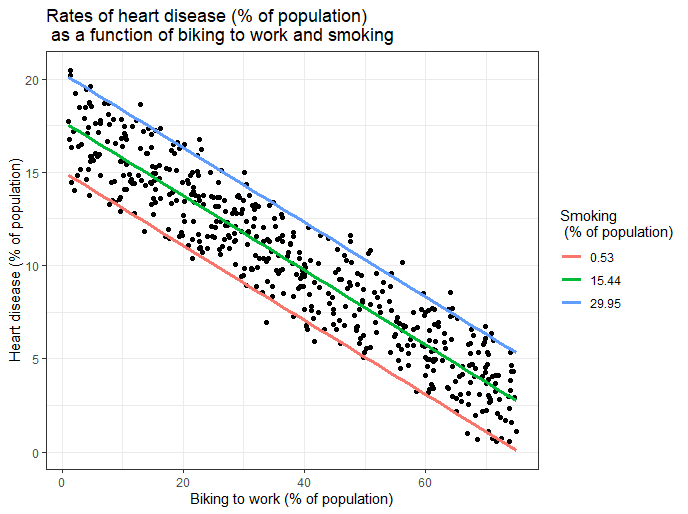
在这里,我们计算了因变量(心脏病)在骑行上班人数百分比的整个观察值范围内的预测值。
为了将吸烟对自变量的影响包括在内,我们计算了这些预测值,同时将吸烟保持在最小值不变,的意思是,以及观察到的最大吸烟率。
关于多元线性回归的常见问题
- 什么是回归模型?
-
回归模型是一种统计模型,用于估计一个依赖项之间的关系变量和一个或多个自变量使用一条线(或在两个或多个自变量的情况下一个平面)。
当因变量是定量的时,可以使用回归模型,但在逻辑回归的情况下,因变量是二进制的。
- 什么是多元线性回归?
-
多元线性回归是一种回归模型,用一条直线估计一个定量因变量和两个或多个自变量之间的关系。
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
贝文斯,R.(2022年11月15日)。多元线性回归|快速指南(示例)。Scribbr。检索于2022年12月18日,来自//www.charpingshvac.com/statistics/multiple-linear-regression/
