类型I和类型II错误|差异,例子,可视化
在统计数据,一个第一类错误是假阳性结论,而第二类错误是错误的否定结论。
做统计决策总是涉及不确定性,因此,在统计过程中,犯这些错误的风险是不可避免的假设检验.
第一类错误的概率是显著性水平,即α (α),而犯第二类错误的概率为β (β)。这些风险可以通过在研究设计中仔细规划来最小化。
- 第一类错误(假阳性):检测结果显示你感染了冠状病毒,但实际上你没有。
- 第二类错误(假阴性):检测结果说你没有感染冠状病毒,但你确实感染了。
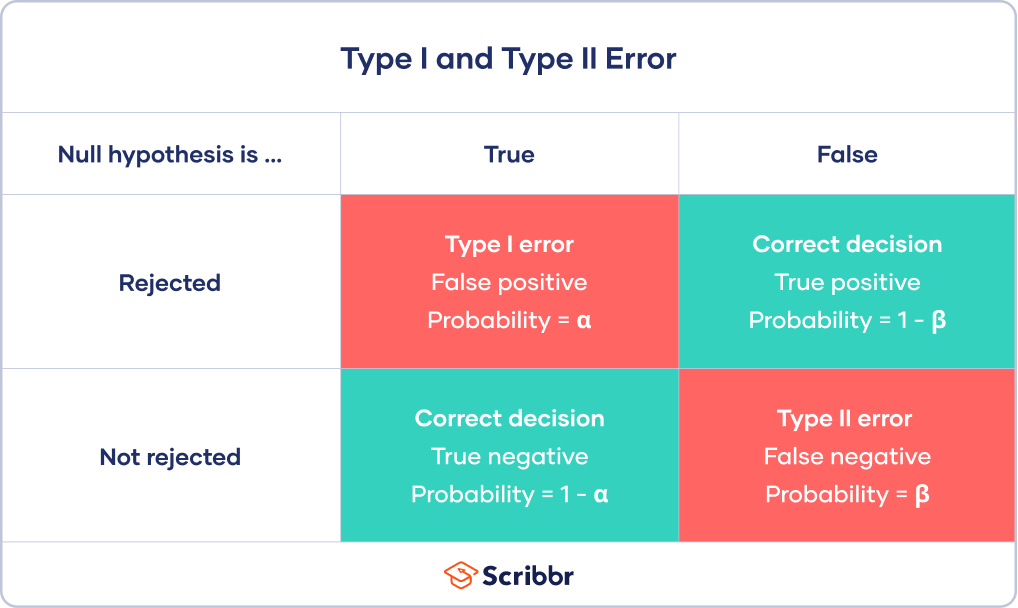
统计决策错误
使用假设检验,你可以决定你的数据是否支持或反驳你的研究预测零假设和替代假设.
假设检验始于组间无差异或总体变量之间无关系的假设零假设.这是总是和备择假设这是你对组间实际差异或组间真实关系的研究预测变量.
在这种情况下:
- 零假设(H0这种新药没有药效效果疾病的症状
- 替代假设(H1这种药对减轻这种疾病的症状有效。
然后,您可以根据您的数据和a的结果来决定是否可以拒绝零假设统计检验.因为这些决定是基于概率的,所以总会有得出错误结论的风险。
- 如果你的结果显示统计显著性这意味着,如果零假设成立,它们不太可能发生。在这种情况下,你会拒绝零假设。但有时,这实际上可能是第一类错误。
- 如果你的发现没有显示出统计显著性,那么如果零假设为真,它们就有很高的概率出现。因此,你无法拒绝零假设。但有时,这可能是第二类错误。
第二类错误发生在你得到假阴性结果时:你得出药物干预没有改善症状的结论,但实际上它确实改善了症状。你的研究可能错过了关键的改善指标,或者将任何改善归因于其他因素。
第一类错误
第一类错误是指在零假设为真时拒绝它。这意味着得出结论,结果是统计上显著而在现实中,它们的出现纯粹是偶然的,或者是由于不相关的因素。
犯此错误的风险是显著性水平(或α)你选择。这是您在研究开始时设置的值,用于评估获得结果的统计概率(p值)。
显著性水平通常设置为0.05或5%。这意味着你的结果只有5%的概率发生,或者更少,如果零假设是真的。
如果p价值的值低于显著性水平,这意味着你的结果在统计上显著且与备择假设一致。如果你的p值高于显著性水平,则认为您的结果在统计上不显著。
然而,pValue表示如果零假设为真,那么结果发生的概率为3.5%。因此,仍然存在犯第一类错误的风险。
为了降低第一类错误概率,可以简单地设置一个较低的显著性水平。
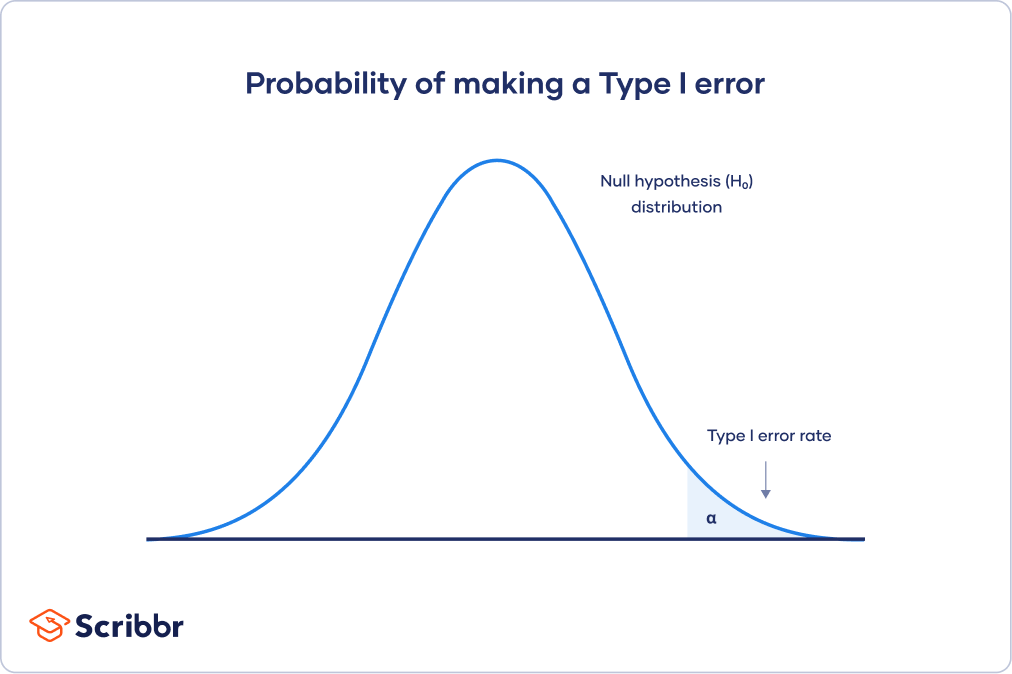
第一类错误率
下面的原假设分布曲线显示了在新样本中重复研究且原假设在样本中成立时获得所有可能结果的概率人口.
在尾部,阴影区域代表alpha。它也叫做a临界区在统计数据。
如果你的结果落在这条曲线的临界区域,它们被认为具有统计学意义,零假设被拒绝。然而,这是一个假阳性结论,因为零假设在这种情况下实际上是正确的!
第二类错误
第二类错误是指当零假设为假时不拒绝它。这与“接受”零假设不太一样,因为假设检验只能告诉你是否拒绝零假设。
相反,第二类错误是指在实际存在影响时未能得出结论。事实上,你的学习可能还不够统计能力检测一定大小的效应。
功率是测试能够正确检测到实际效果的程度在那里就是其中之一。功率水平为80%或更高通常被认为是可以接受的。
第二类错误的风险与研究的统计能力成反比。统计功率越高,出现第二类错误的概率就越低。
然而,如果一个效应小于这个大小,就可能发生第二类。由于统计能力不足,在您的研究中不太可能检测到较小的效应量。
统计功率由以下因素决定:
为了(间接地)降低第二类错误的风险,您可以增加样本量或显著性水平。
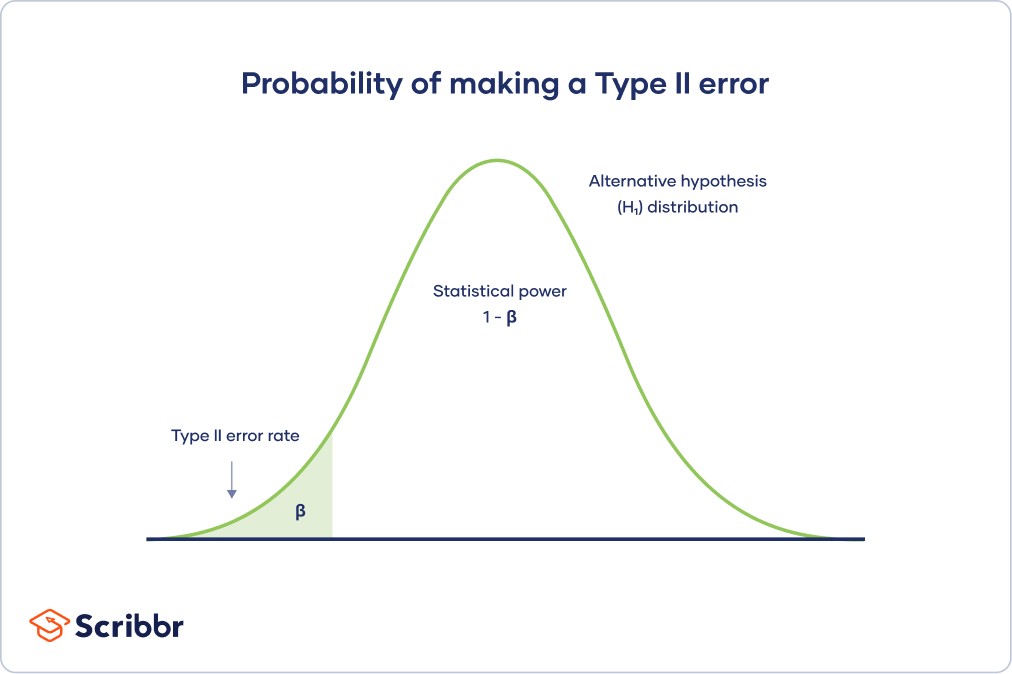
第二类错误率
下面的备择假设分布曲线显示了在新样本中重复研究且备择假设为真时获得所有可能结果的概率人口.
II型错误率为β (β),由左侧阴影区域表示。曲线下的剩余面积表示统计幂,即1 - β。
增加测试的统计能力可以直接降低犯第二类错误的风险。
第一类错误和第二类错误之间的权衡
第一类错误率和第二类错误率相互影响。这是因为显著性水平(第一类错误率)影响统计能力,与第二类错误率成反比。
这意味着在I型和II型错误之间有一个重要的权衡:
- 设置较低的显著性水平可以降低I类错误风险,但会增加II类错误风险。
- 增加测试的强度可以降低第二类错误风险,但会增加第一类错误风险。
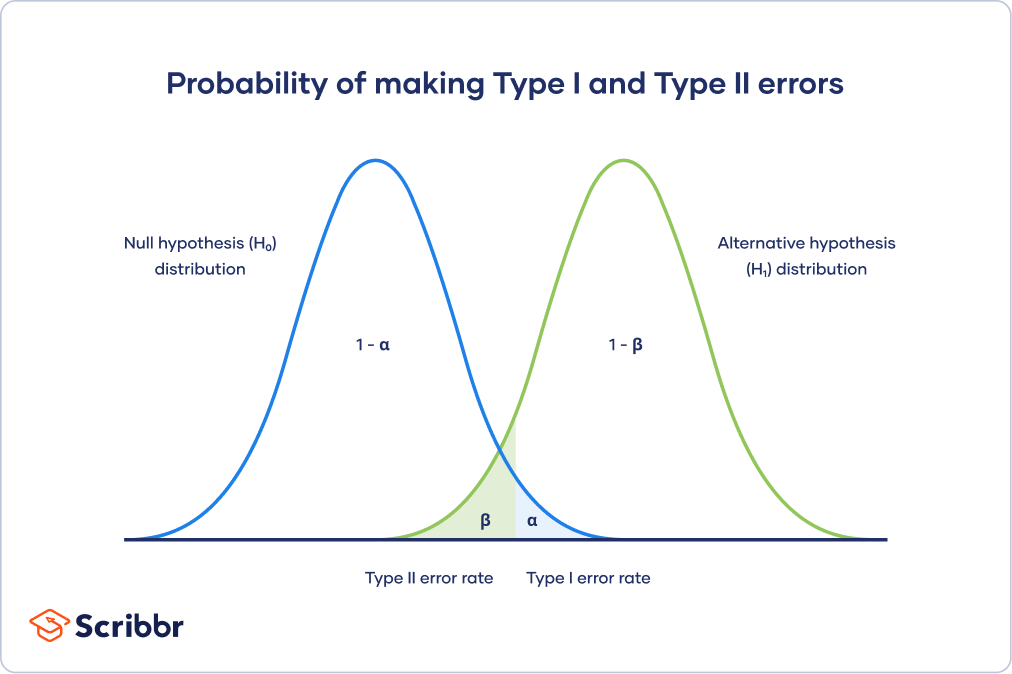
这种权衡如下图所示。它显示了两条曲线:
- 的零假设分布显示了零假设成立时所有可能的结果。对于这个分布上任意一点的正确结论意味着不拒绝原假设。
- 的可选假设分布给出了备择假设成立时所有可能的结果。这个分布上任意一点的正确结论意味着拒绝原假设。
第一类和第二类错误发生在这两种分布重叠的地方。蓝色阴影区域表示类型I的错误率,绿色阴影区域表示类型II的错误率。
通过设置类型I错误率,还可以间接影响类型II错误率的大小。
在犯第一类和第二类错误的风险之间取得平衡是很重要的。减少alpha总是以增加beta为代价,并且反之亦然.
第一类错误和第二类错误哪个更严重?
对于统计学家来说,第一类错误通常更糟糕。然而,在实际应用中,根据你的研究背景,这两种类型的错误都可能更糟。
第一类错误是指错误地违背了零假设的主要统计假设。这可能导致新的政策、做法或治疗不充分或造成资源浪费。
相比之下,第二类错误意味着不能拒绝零假设。这可能只会导致错失创新机会,但也会产生重要的实际后果。
关于第一类和第二类错误的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
班达里,P.(2022年11月11日)。类型I和类型II错误|差异,例子,可视化。Scribbr。检索于2022年12月14日,来自//www.charpingshvac.com/statistics/type-i-and-type-ii-errors/
