另类投资会议是如何计算的?
的Akaike信息标准的计算模型和参数的个数的最大对数似(K)用来达到这一可能性。AIC函数2 k - 2(对数似)。
低AIC值表明更好的选择模型,模型与delta-AIC(两者的区别AIC值相比)超过2被认为是明显好于模型相比。
的Akaike信息标准的计算模型和参数的个数的最大对数似(K)用来达到这一可能性。AIC函数2 k - 2(对数似)。
低AIC值表明更好的选择模型,模型与delta-AIC(两者的区别AIC值相比)超过2被认为是明显好于模型相比。
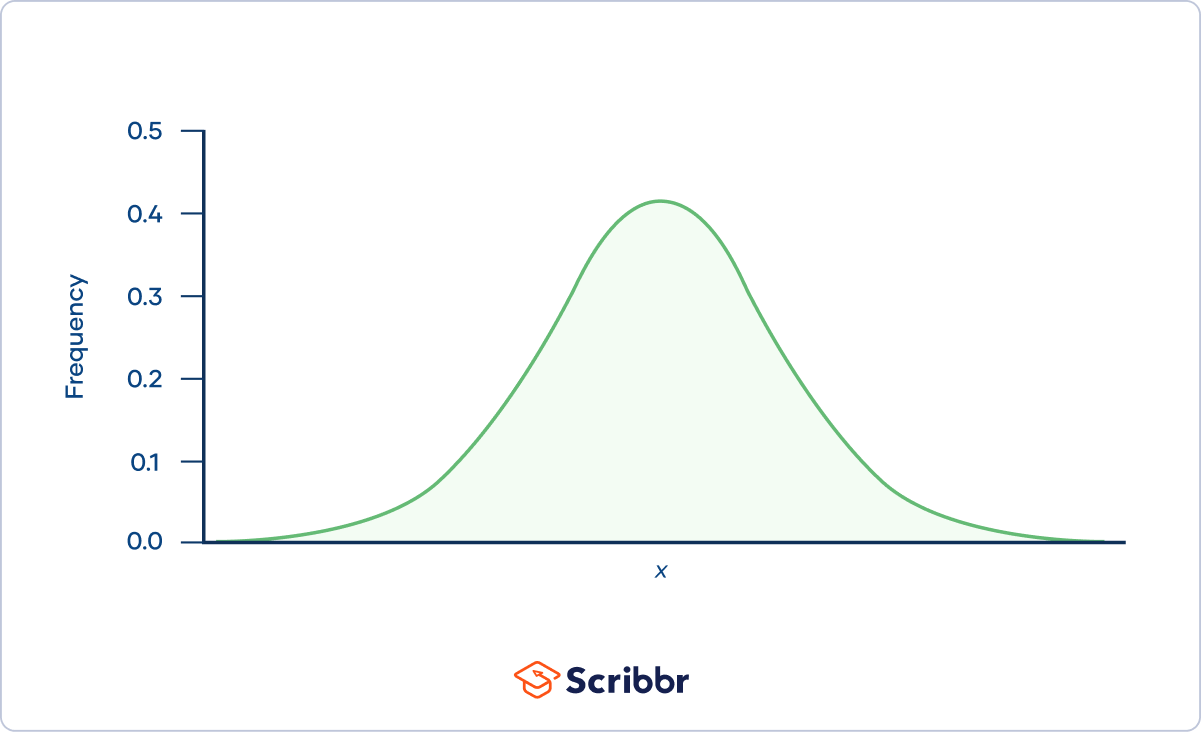
概率是相对频率在无限的试验。
例如,一枚硬币落在正面的概率是5,这意味着如果你抛硬币无限次,它将降落在一半的时间。
自做无限的时代是不可能的,相对频率通常是作为概率的估计。如果你抛硬币1000次,507头,相对频率,.507,是一个很好的估计的概率。
您可以使用CHISQ.INV.RT ()函数来找到一个卡方在Excel临界值。
例如,计算卡方测试的关键值df= 22和α= . 05,点击任何空白单元和类型:
= CHISQ.INV.RT (0.05, 22)
您可以使用chisq.test ()函数执行卡方检验的独立在r .给列联表的矩阵“x”的论点。例如:
m =矩阵(data = c (89、84、86、9、8、24), nrow = 3, ncol = 2)
chisq。te年代t(x= m)
您可以使用CHISQ.TEST ()函数执行卡方检验的独立在Excel中。它有两个参数,CHISQ。测试(observed_range expected_range),并返回p价值。
卡方拟合优度检验通常用于遗传学。一个常见的应用程序,以检查是否两个基因(即有关。,如果分类是独立的)。当基因有关,一个基因的等位基因遗传影响另一个基因的等位基因遗传。
假设你想知道豌豆的基因结构(R =, =皱纹)和颜色(Y =黄色,Y =绿色)是有联系的。你执行一个双因子杂种介于两个杂合的(/一块一块豌豆植物。假设你正在测试的实验是:
你观察100豌豆:
计算期望值,你可以做一个庞氏表。如果两个基因是分离的,每个基因型组合的概率是相等的。
| 变化中 | 变化中 | 变化中 | 变化中 | |
| 变化中 | RRYY | RrYy | RRYy | RrYY |
| 变化中 | RrYy | rryy | Rryy | rrYy |
| 变化中 | RRYy | Rryy | RRyy | RrYy |
| 变化中 | RrYY | rrYy | RrYy | rrYY |
预期表型比例因此9轮和黄色:3轮和绿色:3皱纹和黄色:1皱纹和绿色。
从这一点,你可以计算100豌豆的预期表型频率:
| 表型 | 观察到的 | 预期 |
| 圆的和黄色的 | 78年 | 100 * (9/16)= 56.25 |
| 圆的和绿色 | 6 | 100 * (3/16)= 18.75 |
| 皱纹和黄色 | 4 | 100 * (3/16)= 18.75 |
| 皱纹和绿色 | 12 | 100 * (1/16)= 6.21 |
| 表型 | 观察到的 | 预期 | O−E | (O−E)2 | (O−E)2/ E |
| 圆的和黄色的 | 78年 | 56.25 | 21.75 | 473.06 | 8.41 |
| 圆的和绿色 | 6 | 18.75 | −12.75 | 162.56 | 8.67 |
| 皱纹和黄色 | 4 | 18.75 | −14.75 | 217.56 | 11.6 |
| 皱纹和绿色 | 12 | 6.21 | 5.79 | 33.52 | 5.4 |
Χ2= 8.41 + 8.67 + 11.6 + 5.4 = 34.08
因为有四组(黄色,绿色,皱纹和黄、皱纹和绿色),有三个自由度。
为α= . 05和显著性检验dfΧ= 32关键值是7.82。
Χ2= 34.08
关键值= 7.82
的Χ2值大于临界值。
的Χ2值大于临界值,所以我们拒绝零假设的人口后代继承的所有可能的基因型的概率是相同的组合。之间有显著差异的观察和预期基因型频率(p< . 05)。
数据支持备择假设,没有后代继承所有可能的基因型组合的概率相等,这表明基因有关
您可以使用chisq.test ()函数执行卡方拟合优度检验r .给“x”的观测值参数,给预期值的“p”的论点,并设置”重新调节。p为true。例如:
chisq。te年代t(x= c(22,30,23), p = c(25,25,25), rescale.p = TRUE)
找到四分位数的一个概率分布,可以使用分布的分位数函数。
您可以使用分位数()函数四分位数在r .如果您的数据被称为“数据”,然后“分位数(数据,概率= c(二十五分,5,综合成绩),类型= 1)”将返回三个四分位数。
您可以使用四分位数()函数四分位数在Excel中。如果你的数据列,然后单击任何空白单元和类型”=四分位数(1),一个“第一四分位数,”=四分位数(2),一个“第二个四分位数,和”=四分位数(3),一个“第三四分位数。
您可以使用皮尔森()函数计算皮尔森相关系数在Excel中。如果你的变量是在A和B列,然后单击任何空白单元和类型”皮尔森(A, B: B)”。
没有函数直接测试相关的意义。
您可以使用和()函数计算皮尔森相关系数在r .测试的意义关联,您可以使用cor.test ()函数。
时你应该用皮尔逊相关系数(1)是线性的关系,(2)变量都是定量的,(3)正态分布和(4)没有离群值。
的皮尔森相关系数(r)是最常见的方法测量线性相关性。1和1之间的数字,措施的强度和方向两个变量之间的关系。
的e在泊松分布公式2.718代表数量。这个数字被称为欧拉常数。你可以简单的用e2.718当你计算一个泊松概率。欧拉常数是一个非常有用的数量和在微积分尤为重要。
的备择假设通常缩写为H一个或H1。当备择假设编写使用数学符号,它总是包含一个不平等的象征(通常≠,但有时<和>)。
的零假设通常缩写为H0。当使用数学符号零假设时,它总是包含一个平等的象征(通常=,但有时≥或≤)。
的t分布第一次被统计学家威廉·希利戈塞特以笔名“学生”。
您可以使用T.INV ()函数的临界值t为单侧测试在Excel中,您可以使用T.INV.2T ()为双尾测试功能。
0.05 = T.INV.2T (29)
您可以使用qt ()函数的临界值t在r的函数给出了重要价值t单侧检验。如果你想要的临界值t双尾检验,划分显著性水平由两个。
qt (p= .025,df= 29)
您可以使用摘要()函数来查看R²线性模型的r .您将看到“平方”输出的底部附近。
收拾你的缺失的数据,你的选择通常包括接受、删除或重建丢失的数据。
有两个步骤来计算几何平均数:
在计算几何平均数之前,请注意:
相关系数总是介于1和1之间。
系数的符号告诉你的方向关系:正数意味着变量在同一个方向改变,而一个负值意味着他们在相反的方向变化。
一个数的绝对值等于数量没有信号。相关系数的绝对值告诉你的大小关系:绝对值越大,相关性越强。
一个相关系数是一个数字,描述变量之间的关系的强度和方向。
不同类型的相关系数可能适合您的基于他们的数据水平的测量和分布。的皮尔逊积差相关系数(皮尔森的r)通常用于评估两个定量变量之间的线性关系。
一个数据集往往没有模式,一种模式或一个以上的模式——这一切都取决于有多少不同的值重复最频繁。
你的数据:
两种最常见的计算方法四分位范围是独家的和包容的方法。
排除法排除了中间当识别Q1和Q3,而包容的方法包括中值作为一个值确定数据集的子集。
为每个这些方法,你需要不同的程序寻找中值,Q1和Q3取决于样本大小或奇数。的独家方法最适合偶数编号的样本大小,而包容的方法通常是使用奇数样本大小。
统计测试如方差或测试方差分析(方差分析)使用示例方差评估小组不同的人群。他们用样本的方差来评估是否他们来自人口显著不同于对方。
名义上的数据是数据,可以贴上标签或互斥的分类变量。这些类别不能命令以一种有意义的方式。
例如,名义变量的首选的运输方式,你可能类别的汽车,公共汽车,火车,电车和自行车。
的置信水平的百分比乘以你希望接近相同的估计如果再次运行您的实验或重新取样人口以同样的方式。
的置信区间包括的上下界估计你希望找到在给定的置信水平。
举个例子,如果你估计95%置信区间的平均比例女性每年出生的婴儿基于随机样本的婴儿,你会发现一个上界的0.56和0.48的下界。这些都是上下界的置信区间。置信水平为95%。
α值,或的门槛统计显著性,是任意的使用取决于你的价值的研究领域。
在大多数情况下,研究人员使用一个α为0.05,这意味着有一个小于5%的几率被测试的数据可能发生在零假设下。
您所使用的检验统计量将取决于统计测试。
你可以选择正确的统计检验看你有什么类型的数据收集和你想要测试什么类型的关系。
在统计中,模型选择是一个过程人员使用比较的相对价值不同的统计模型,并确定哪一个是最适合观测数据。
的Akaike信息标准是一种最常见的模型选择方法。AIC权重模型的预测能力的观测数据对参数的数量模型需要达到的精度水平。
AIC模型选择可以帮助研究人员找到一个模型来解释观察到的变化数据,同时避免过度拟合。
在统计中,模型是一个或多个的集合独立变量和他们的相互作用预测,研究人员使用试图解释因变量的变化。
你可以使用一个测试模型统计检验。对比不同模型适合您的数据,您可以使用Akaike信息标准模型选择。
的Akaike信息标准是一个数学测试用于评估模型与数据的吻合程度是为了描述。它惩罚模型使用更多独立变量(参数)来避免过度学习。
AIC通常是用来比较不同模型之间的相对拟合优度考虑,然后选择最好的模型与数据的吻合程度。
多元线性回归是一个回归模型,估计之间的关系量化因变量和两个或两个以上的独立变量使用一条直线。
一个回归模型是一种统计模型,估计一个依赖之间的关系变量和一个或多个自变量使用一行(或一架飞机的两个或两个以上的独立变量)。
可以使用回归模型定量因变量时,除了逻辑回归的情况下,因变量是二进制。
一个单样本t检验是用来比较一个人口到一个标准的值(例如,确定是否一个特定城市的平均寿命是不同于国家平均水平)。
一个配对t检验是用来比较一个人口之前和之后的一些吗实验干预或在两个不同的时间点(例如,衡量学生成绩在考试之前和之后被教材料)。
你所选择的学习任务取决于你正在研究一组或两组,以及是否你关心的方向不同组的意思。
如果你正在研究一组,使用配对t检验比较组意味着随着时间的推移或干预后,或者使用单样本t检验比较组的意思是一个标准的价值。如果你正在研究两组,使用两个示例学习任务。
如果你想知道是否存在差异,使用双尾检验。如果你想知道一个组的意思是大于或小于其他使用left-tailed或right-tailed单侧检验。
我们的团队可以帮助学生通过毕业:
Scribbr专业编辑进一步研究文档。我们校对:
的Scribbr剽bob综合app官网窃检查程序是由元素的Turnitin的相似度检查器,即剽窃检测软件和互联网档案馆和优质的学术出版物内容的数据库。
的Scribbr引文发电机使用开源开发的吗引用样式语言(CSL)项目和弗兰克·班尼特citeproc-js。这是许多其他流行的引文所使用的相同的技术工具,包括Mendeley和Zotero。bobapp官方下载
你可以找到所有的引用风格和地区Scribbr引用中使用发电机在我们公开访问在Github库。





 。
。 和
和 。
。